
生成式AI在內容創作和客服上已經展現驚人的力量,在市場研究或市調上的潛力更是無窮。本文介紹生成式AI應用在市場研究上的4種新方式,行銷人員如果善加利用,可以對市場以及客戶有更為深入而精準的了解。

關於本文藝術作品/卡爾森.戴維斯.布朗(Carson Davis Brown)的創作靈感來自美國拼布工藝與行為藝術的傳統,他在大型量販店中組合現成物品,創造出一種遊擊式的裝置藝術。
在所有的管理職能中,行銷可能是最容易受到生成式AI顛覆的領域。學者和從業人員早已看見這項科技的潛力,一直在探索應用於客服和內容創作的新方式。但是最近,商業界開始注意到它可能對其他行銷活動帶來的影響。其中最令人興奮的行銷活動是市場研究——亦即企業蒐集數據及深入了解顧客與競爭對手的方式。
本文觀念精粹
機會:生成式AI即將徹底改變市場研究——亦即企業蒐集數據及深入了解顧客與競爭對手的方式。行銷人員需要了解並善用各種可能性。
研究:作者找出將生成式AI應用在市場研究上的4種不同類型—(1)強化現有實務、(2)取代現有實務、(3)填補現有缺口,以及(4)創造新型態的數據和見解。
未來方向:隨著行銷界開始運用生成式AI,他們需要充分發揮這項新科技的優勢,同時確保生成式AI制定的策略是建立在公平、準確、真實的顧客見解之上。
這兩年來,我們深入研究正在探索生成式AI如何應用於市場研究的企業,並直接與它們合作。我們可以告訴大家,這個領域即將出現重大的變革。若妥善運用,這項科技能為企業帶來前所未有的機會,包括了解顧客並與他們互動、更精準地評估競爭環境,以及把數據驅動的決策深入擴大到組織的各個層面。
“AI為企業帶來前所未有的機會,包括了解顧客並與他們互動、更精準評估競爭環境,以及擴大數據驅動的決策。
我們的研究找出4種不同的機會類型。第一種是「強化現有實務」,使它們變得更快、更便宜或更容易擴大規模;第二種是利用合成數據(由AI創造、而非透過調查或訪談蒐集的真人偏好或行為數據)來「取代現有實務」;第三種是取得傳統數據無法提供的見解和證據,以「填補目前對市場了解的缺口」;第四種仍在萌芽階段,是「創造新型態的數據和見解」。
本文將提出一個架構,協助領導人和企業在這片新領域順利發展。我們將說明生成式AI如何開始及持續改變市場研究、如何充分利用新機會,以及如何留意這項科技的限制和其新應用所涉及的道德議題。
強化現有實務
企業在蒐集顧客和市場見解時,常因成本相對高昂,以及時程漫長而頭痛。那麼,生成式AI如何同時解決這兩個問題?
根據我們的研究以及企業合作的經驗,我們開發出一套系統性的方法來尋找使用案例。這個方法把生成式AI的4大核心能力——統整、編寫程式碼(電腦程式設計)、人機互動、寫作——應用到市場研究流程的各個階段。為了簡化說明,我們把流程只分成3大階段:找出機會及設計研究計畫;蒐集及分析數據;撰寫報告及傳播資訊和見解(請見「生成式AI如何強化當前的市場研究實務」)。例如,生成式AI的資訊統整能力,可在第一階段用於摘要文獻和先前的研究,在第二階段用來從訪談和新數據中萃取發現,並在第三階段闡述重點。而且,生成式AI做這些工作的速度可能遠比人類還快。
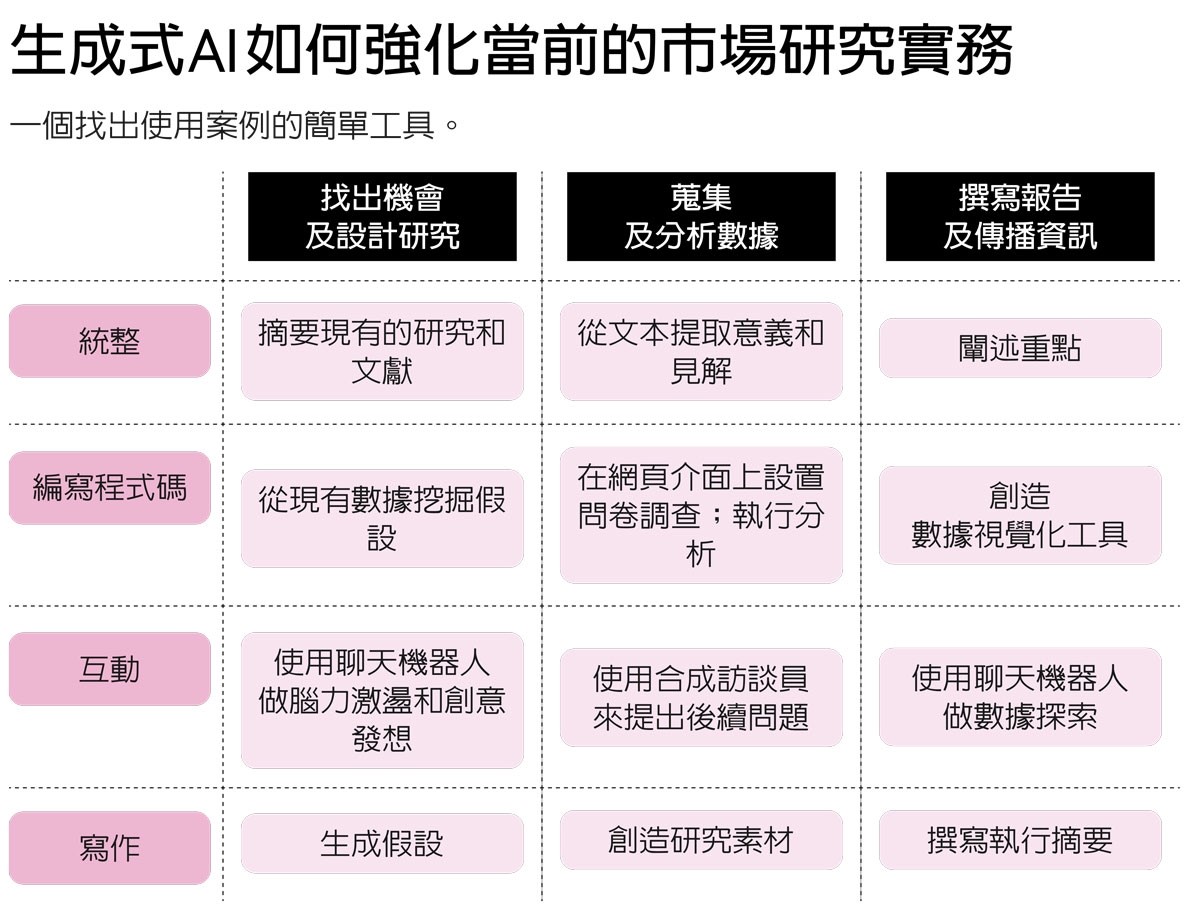
企業究竟如何運用生成式AI來強化現有實務?最近我們與柯斯特的公司GBK Collective〔一家與頂尖商學院的教授和《財星》(Fortune)500大企業有深厚關係的行銷策略與見解公司〕合作的調查揭開了答案。我們在這項調查中蒐集170位市場研究從業人員和用戶的回應,發現45%的受訪者已經在目前的數據和見解活動中使用生成式AI;另有45%表示他們正在規畫未來採用。
這項調查發現了一些有趣的重要趨勢。不出所料,逾70%的受訪者表示,他們對生成式AI可能帶來的副作用和挑戰有疑慮。這些疑慮包括可能產生偏誤或不準確的資訊、安全和隱私風險,以及把生成式AI整合到現有實務需要額外時間和精力。類似比例的受訪者也擔心,生成式AI可能造成技能落差,甚至取代數據和見解的專業人員。
話雖如此,許多受訪者就像我們合作過的從業人員一樣,對這項科技抱持極為正面的態度,而且已經開始擁抱它。62%目前在工作中使用生成式AI的受訪者告訴我們,他們用它來統整冗長的訪談逐字稿和其他文件,這原本是一個費時費力的過程;58%的人用它來分析數據;54%的人用它來撰寫報告。整體而言,受訪者似乎對生成式AI能以多種方式協助他們完成工作感到興奮。超過80%的人認同,它可能大幅提升個人生產力和效率,也覺得把它整合到工作流程中對維持競爭力很重要。同樣比例的受訪者表示,他們相信生成式AI將改善工作,推動重大創新,由此對整個產業產生正面影響。他們說,生成式AI之所以能達成這點,是因為它能讓大家更快完成任務、專注於能增添更多價值的任務,並騰出更多時間來解讀數據及說故事。更廣泛來說,它將提高工作的品質、準確度,以及客製化的程度。
市場研究的新創公司已經開始進入這個領域。其中一家名為Meaningful的公司,目標是利用生成式AI來「大幅強化」市場研究,包括用它來設計客製化的問卷調查、把問卷調查發送給受訪小組、做質化訪談,以及分析結果。另一家名為Outset.ai的公司則是把焦點放在生成式AI如何針對消費者的需求和行為提出問題,而非答案——這是個很有前景的概念。它的AI主導研究平台會根據受訪者先前的回答,動態地提出新問題,從而獲得更有見解的答案,這種做法結合了自動化調查工具的速度和規模,以及傳統訪談的深度。Outset.ai的共同創辦人暨執行長艾倫.康納(Aaron Cannon)是根據一個特別重要的發現來打造公司:當生成式AI只需專注與人對話時,人們會傾訴想法、經驗和感受,而AI產生幻覺的問題幾乎都消失了。
WeightWatchers(Outset.ai的客戶)的研究團隊發現,相較於接受真人訪談,受訪者接受AI訪談時往往更願意坦誠相告,因為某些偏誤效應降低了。該公司的前用戶體驗研究長威爾.瑞丁格(Wil Readinger)對生成式AI充滿熱情。他表示,研究人員不再需要二擇一:不是用訪談蒐集更豐富的情境化數據,就是用調查觸及廣大的範圍。相反地,他們現在有了第三種選擇,用他的話來說,就是「兩者兼得!」。
取代現有實務
在行銷領域,生成式AI最創新的應用之一是產生及分析所謂的「合成數據」(synthetic data)——這種人造數據能模擬真人的行為和偏好。企業可以透過市面上常見的生成式AI程式來做到這點,但它們也可以運用從傳統研究、制式數據(syndicated data)、顧客關係管理系統(CRM systems)、交易資訊中已蒐集到的整合數據(aggregate data),來開發及訓練自己專屬的模型。接著,合成數據可用來模擬各種顧客或競爭者的反應,凸顯潛在的痛點,以及消費者在使用產品或服務的不同階段所尋求的效益。在我們的調查中,高達81%的受訪者表示,他們已經在使用或計畫使用生成式AI來製作合成數據。一位受訪者提到,他們打算「根據我客戶的目標受眾,來創造合成的受眾角色,讓我的團隊可以與它們互動」。
“在行銷領域,生成式AI最創新的應用之一,是產生和分析所謂的「合成數據」。
藉由建立詳細的假想顧客樣貌和可能情境,這些模型可以幫行銷人員更準確預測需求和偏好,做出更有效的決策。但它們當然無法複製人類行為的全部深度和不可預測性。我們的受訪者非常清楚這個缺點:只有31%的人覺得生成式AI產生的數據價值「極高」——這是我們調查中滿意度最低的領域之一。不過,值得注意的是,研究顯示,生成式AI可以在幾種情況下提高合成數據的品質:在提示中輸入問答範例、允許它從過去研究的知識庫提取與每個問題有關的內容,以及微調其參數使它更符合現有數據。
新公司與老字號公司都在探索合成數據的潛力。例如,新創公司Evidenza已經進行60多項驗證研究,比較多個行業的合成結果與傳統研究結果。在一項研究中,它與安永(EY)合作進行雙盲測試,這是科學研究的黃金標準,雙方在研究結束前都不知道對方的結果。安永提供Evidenza其年度品牌調查的問卷以及目標受眾(美國營收逾10億美元公司的執行長)的詳細數據,但保留了實際調查結果,以便日後做為比較的基準。Evidenza隨後根據目標受眾樣貌,創造1,000多個合成角色,讓它們回答調查的問題。「結果令人驚嘆,」安永的美洲行銷長湯妮.克萊頓—海恩(Toni Clayton-Hine)告訴我們,「結論有95%相同,相關性非常強,許多情況下數字幾乎一模一樣。」
生成式AI不僅產出結構化的量化數據。2024年美國威斯康辛商學院(Wisconsin School of Business)的一項研究顯示,它也能產生深入的質化數據。特別值得一提的是,它能夠對自己創造的合成受訪者(比如用來模擬理想顧客)做深入又有洞見的訪談。目前已有幾位研究人員與經理人成功以這種方式使用生成式AI。總部位於葡萄牙的新創公司Synthetic Users就是這類服務供應商的好例子。
“生成式AI能夠對它創造的合成受訪者(比如用來模擬理想顧客)做有洞見的訪談。
當然,任何想要採用客製化方法來創造合成數據的公司,都必須與生成式AI程式分享一些內部獨有的資訊,這讓一些企業感到不安。為了緩解它們的顧慮,所有主要的生成式AI供應商都提供付費的企業版模型,這些模型不會與其他公司分享公司內部獨有的數據或見解。有些供應商還幫公司開發可以完全由自己控制的「小型」生成式AI模型。例如,新創公司Rockfish Data允許企業利用內部數據集,來開發及訓練自己的客製化生成式AI模型,這種方法能完全維持數據和模型的私密性。這些模型可能很小,但一些使用者並不小:美國陸軍和國土安全部都是Rockfish Data的客戶。
再次強調,這方面也有優缺點需要權衡:小型生成式AI模型大多只能處理結構化或半結構化的數據(數字型或類別型數據),缺乏公開模型那種豐富的訓練數據集優勢;而公開模型還可以處理比較不結構化的質化數據。對一些公司來說,用內部獨有數據來微調大型模型可能是有效的折衷方案。
填補現有缺口
即使在號稱數據驅動的組織中,從業人員也常說,多數決策其實沒有經過正式的實證分析,純粹是因為時間或預算不足。但生成式AI可望成為一種全天候的智慧引擎,隨時提供顧客和市場見解——當數據無法取得或取得成本太高時,市場研究人員能立即獲得經驗證據。生成式AI可用於檢驗假設、測試概念及執行策略,並為管理決策提供參考意見。企業甚至可以打造「實驗室」,用來製造客製化的AI模型,以便員工安全又方便地使用這些AI模型來協助整個組織的決策。
在我們的調查中,30%的受訪者表示,他們的公司曾使用生成式AI來引導決策,而這些決策過去不會利用外部的數據和見解。整體而言,81%的受訪者表示,他們正使用或計畫使用生成式AI來「傾聽市場」,讓組織隨時掌握競爭環境的最新狀況。例如,某家公司用它來分析最新趨勢和競爭對手的策略,為決策提供及時的競爭情報;另一家公司則是讓它根據歷史數據和假設,為決策進行預測分析。
許多公司正在嘗試使用合成數據來協助產品創新,通用磨坊(General Mills)就是一例。該公司的創新、科技和品質長蘭內特.夏芙.沃納(Lanette Shaffer Werner)表示:「我們正在研究如何運用合成數據來加快及改善產品發想流程,讓我們在思考如何為消費者提供最佳服務時,更有可能發現真正卓越的構想。」
一些新創公司也投入了合成數據領域。Evidenza提供工具來創造B2B客戶的合成數據,這類客戶是出名地難以接觸。Arena Technologies利用生成式AI以及當地顧客樣貌與偏好的合成數據,幫零售商做出更明智的決策——例如如何針對不同門市量身打造商品。Evidenza運用合成數據,來幫行銷人員做出有關目標客群、市場定位、訊息傳播的決策,其平台也會估算這些選擇的財務影響,提供財務長與營收團隊重視的投資報酬率預測和指標。

創造新型態的數據和見解
內容行銷和銷售圈有句老話:第一印象只有一次機會。不過,這句話可能不再是鐵律了。
我們這麼說是因為,內容行銷人員和銷售人員開始使用生成式AI來打造「數位雙生」——亦即利用公開資訊或內部獨有數據,為個別顧客打造的虛擬分身——以便在接觸真實客戶以前,先測試及調整文件資料與銷售話術。這種做法可以仔細調校行銷方式,因為數位雙生不像真人,它們與行銷人員互動並回答他們問題時,永遠不會疲勞、煩躁或無聊。我們有超過40%的受訪者表示,他們已經在實驗數位雙生技術。例如,一位受訪者指出,在虛擬銷售環境中使用數位雙生來「模擬顧客在不同情境下的購買行為、點擊率、互動模式」,這一切都是為了「幫忙測試市場策略,以及盡力改善用戶體驗」。另有42%的受訪者表示,他們計畫未來要實驗數位雙生技術。
數位雙生在行銷領域的應用正迅速擴展。Arena公司已開發出一款訓練工具,讓B2B銷售人員和顧客的數位雙生互動。CivicSync開發出一種技術,讓客戶(在取得消費者的同意下)追蹤購物、搜尋和其他線上行為,然後為目標用戶建立非常精準的數位雙生。公關公司奧美(Ogilvy)曾在數位雙生上測試創意點子,以確保活動能引起消費者的共鳴。GBK Collective正在嘗試不同的方法,用調查結果來訓練或指導生成式AI製作數位雙生,以便在後續的行銷問題上向數位雙生徵詢意見。這家公司利用過去調查數據的不同組合,來打造各種不同的數位雙生,然後進行測試,看看哪些方法在特定商業研究目標上表現較好或較差。最後,比較測試結果和過去調查的實際回答,來衡量每種方法的成效。
許多公司也在嘗試使用Google的NotebookLM等免費工具,這類工具能打造個人化的「研究助理」,並以競爭對手資訊、相關產業和領域數據、目標客戶樣貌來訓練。這個助理可以協助團隊成員調整話術、產品方案和互動方式,並預測可能的反彈,來幫他們做好接觸顧客的準備。網路安全新創公司Oleria的首席技術客戶經理亨利.梭薩(Henry Sosa,本文作者之一柯斯特是Oleria的顧問),已經為他的銷售和行銷同事建立一系列這樣的生成式AI助理。
學術界也正在關注新的可能性。例如,美國哥倫比亞商學院(Columbia Business School)的一個團隊正在建立一個具有代表性的群組,由2,500個角色組成,而每個角色都是一個真人的數位雙生。這些被模擬的真人會經過一連串的全面測試(包括心理、行為、認知、態度測試),這些測試結果將共同建立一個「基準事實」,讓生成式AI用來創造出數位雙生。它背後的構想是把這個群組當成新研究和調查的虛擬受試者。美國史丹福大學(Stanford University)和Google DeepMind的研究人員共同進行的一項研究顯示,這種做法很有前景。研究團隊先訪問一組人幾個小時,並讓他們完成一系列問卷調查,然後利用訪談逐字稿為每位參與者創造數位雙生。接著,他們讓這些數位雙生回答相同的問卷,也要求真實參與者在兩週後再次回答相同的問題。結果顯示,數位雙生的回答與真人初次回答的相似度達到85%,跟真人第二次回答的相似度相當。
了解局限
生成式AI為行銷人員提供很多可能性,但它仍有許多局限需要正視。誠如前述,我們調查中凸顯的一大顧慮是可能出現偏誤的結果,有77%的受訪者提到這點。任何訓練數據集本身都有偏誤,這可能會扭曲生成式AI的輸出結果,導致對客群或市場趨勢的錯誤描述(不過,目前的調查方法也可能因為多種原因而導致偏誤的結果)。此外,由於生成式AI模型是以現有數據和見解訓練出來的,它們在預測消費者行為的劇變或預見突破性產品創新方面,成效仍不確定。此外,眾所周知,生成式AI模型很容易受到提示結構的影響。舉例來說,我們發現,當它回答選擇題時,選項的順序和標示方法會以難以預測的方式影響它。研究人員應該注意這種效應,就像面對真人受訪者一樣,務必隨機調整問卷調查的所有相關元素,以減少可能的偏誤。
也有人擔憂,生成式AI能否模擬代表性人口樣本的回答。哥倫比亞大學(Columbia University)和史丹福大學的研究人員在2023年的一項研究發現,OpenAI最近大多數模型所表達的觀點,比較偏向自由派或高學歷人士的想法,而不是65歲以上或宗教信仰較虔誠者的想法。這種偏誤不僅可能來自訓練模型的數據,也可能來自調整模型的人為參與,這或許能解釋為何較新的模型愈來愈有偏誤。考慮到這些限制,我們也就不必訝異,美國范登堡大學(Vanderbilt University)詹姆斯.必斯比(James Bisbee)2024年領導的一項研究發現,當合成受訪者參與民調時,他們的回答雖然與真人極為相似,但變化性較小,容易受問題的用字遣詞所影響,而且在3個月期間內的表現不穩定。
合成數據可能也很難有效協助模擬實驗,把受訪者分組,接受不同的條件對待。我們曾經嘗試使用生成式AI來模擬實驗,讓不同的數位受訪者看到產品的不同價格,並詢問他們是否打算購買。結果發現,AI產生的需求曲線不只與真人受訪者的回答不同,而且根本不合常理。
事後看來,原因可能很簡單。真人實驗通常會採用盲測設計,每位受試者不知道其他條件,也不清楚研究目的。這就像現實中的消費者決策情境:消費者通常不會同時看到同一產品以一系列不同價格出售。但是,當盲測設計應用於生成式AI模型的實驗時,會出現所謂的「混淆」(confounding)現象,也就是某個未預期的變數同時與自變數(如價格)和應變數(如購買決策)相關,打亂自變數和應變數之間的關係。在這個訂價實驗中,我們發現,生成式AI難以把產品價格視為隨機,傾向於認為其他變數(如歷史價格或店內其他產品的價格)也會隨著該產品價格而變動,這使得較高價格的購買行為顯得合理,導致價格變化時,合成受訪者的行為幾乎沒什麼變化。
生成式AI在預測消費者對多感官刺激的情緒反應方面,仍然表現不佳。香料公司高砂(Takasago)在嘗試用AI生成的虛擬小組取代真人研究小組時,發現了這點。舉例來說,香氣對生成式AI模型的影響,和對真人的影響截然不同。該公司的顧客見解與市場研究全球副總裁潔蓮娜.勒布雷頓(Jelena Le Breton)告訴我們:「雖然我們的模型能從過去的數據學習,但要預測人類嗅覺偏好的變化仍然很難,因為嗅覺偏好往往與個人經歷和情緒有關。」
行銷新未來
如果生成式AI能每小時用數百種語言與全球數千人交談,而且能從那些對話所產生的數據中,立即提取各種獨特、優質的見解,那麼我們對彼此的了解應該會更深入——而我們打造的產品、服務、體驗非但不會減少人性,反而更有人文溫度。當我們在生成式AI和合成數據時代探索行銷的未來時,行銷界需要維持一個平衡且明辨的觀點。唯有如此,我們才能充分利用這些卓越工具和科技的優勢,同時確保我們的策略是建立在公平、準確、真實的顧客見解之上。
文章來源:哈佛商業評論 5月號

